[Elastic Search란?]
간단히 말하면, 다양한 데이터를 위한 검색 엔진이다.
검색엔진이란 무엇일까? 우리가 흔하게 알고 있는 관계형DB와 비교해서 생각해보자.
관계형 DB는 테이블 안에 행, 열에 맞게 데이터를 쪼개서 넣고 쿼리문으로 데이터를 선별한다.
이와 비교해서 검색엔진은 보다 유연하게 데이터를 넣고, 검색할 수 있다.
[Elastic Search의 필요성]
시스템을 운영하다 보면, 운영 안정성 향상 및 이슈 대응을 위해 로그를 수집하고 분석해야 하는 일이 잦다.
그러나 발생하는 로그는 비정형 데이터인 경우가 많으며, 그 양도 많아 많은 양의 로그에서 인사이트를 도출하는 것이 필요한데
이 때 유용하게 사용할 수 있는 것이 Elastic Search 툴이다.
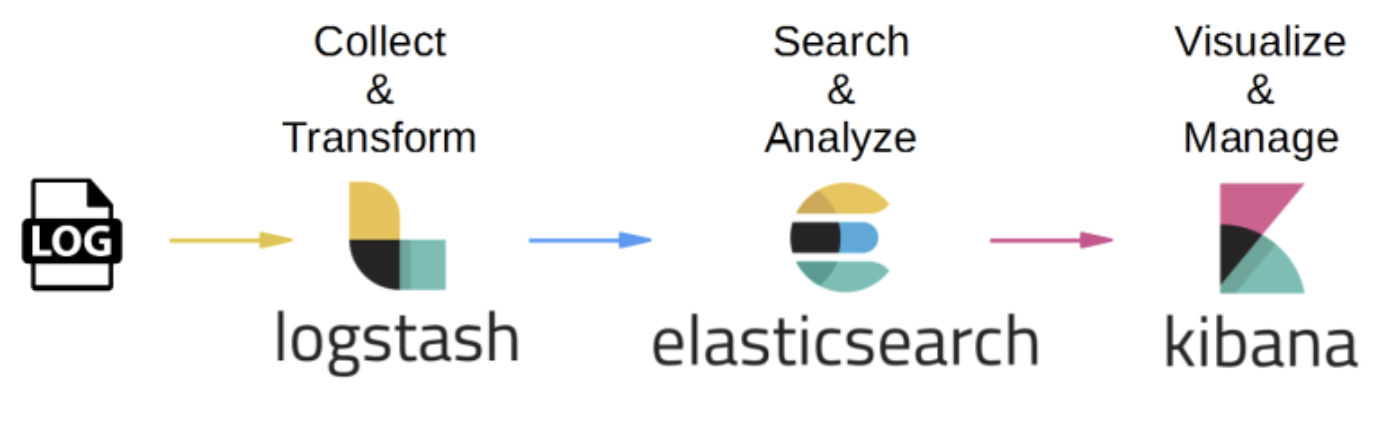
[ELK Stack이란?]
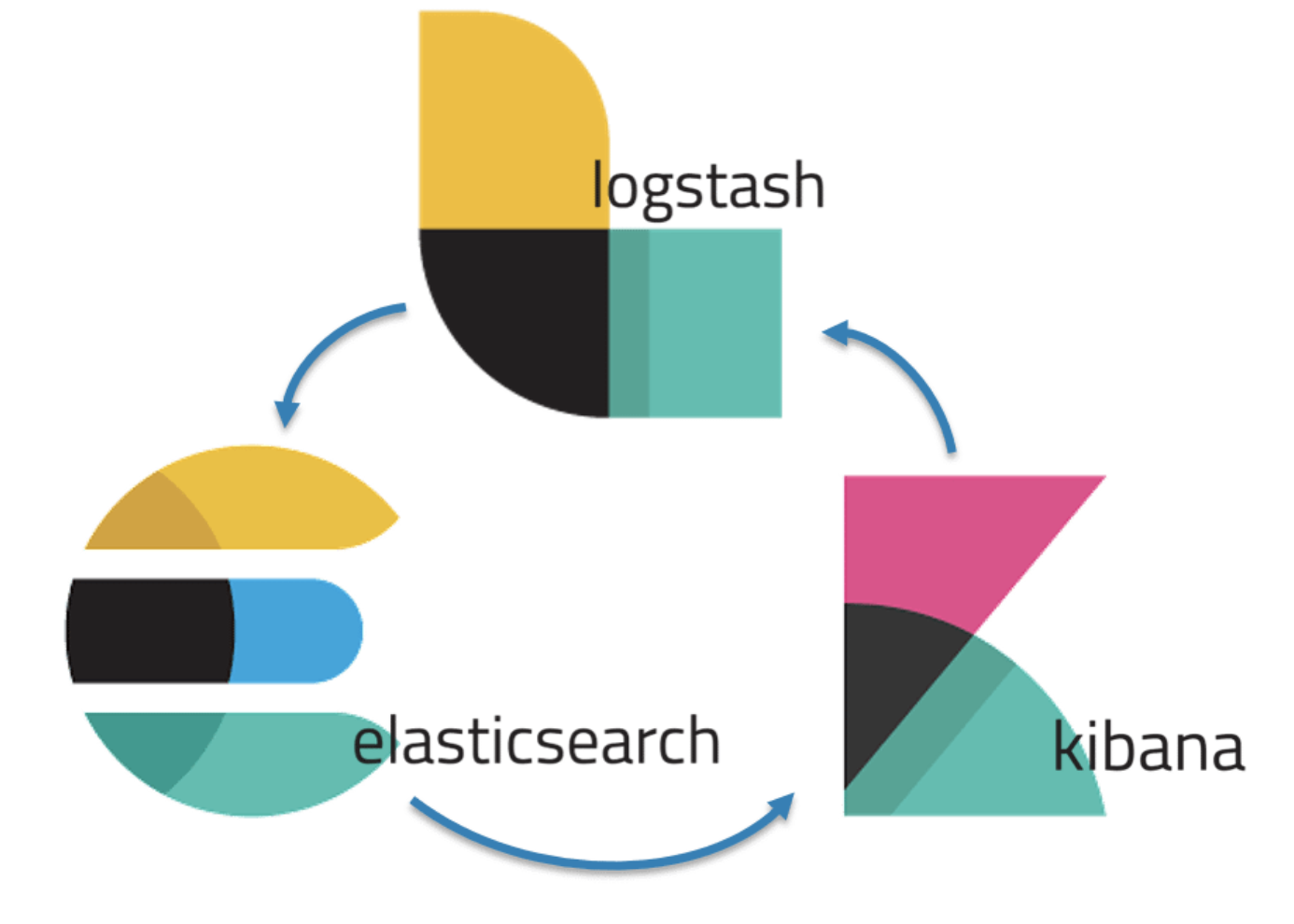
- Elasticserach : Storage 역할 - 데이터 저장/분석/관리
- Logstash : Data Processing 역할 - 서버 내 로그, 웹 등 다양한 소스에서 데이터 수집하여 입력, 데이터 변환/구조 구척, 데이터 출력/송신
- Kibana : Visualize 역할 - Dashboard를 이용한 탐색
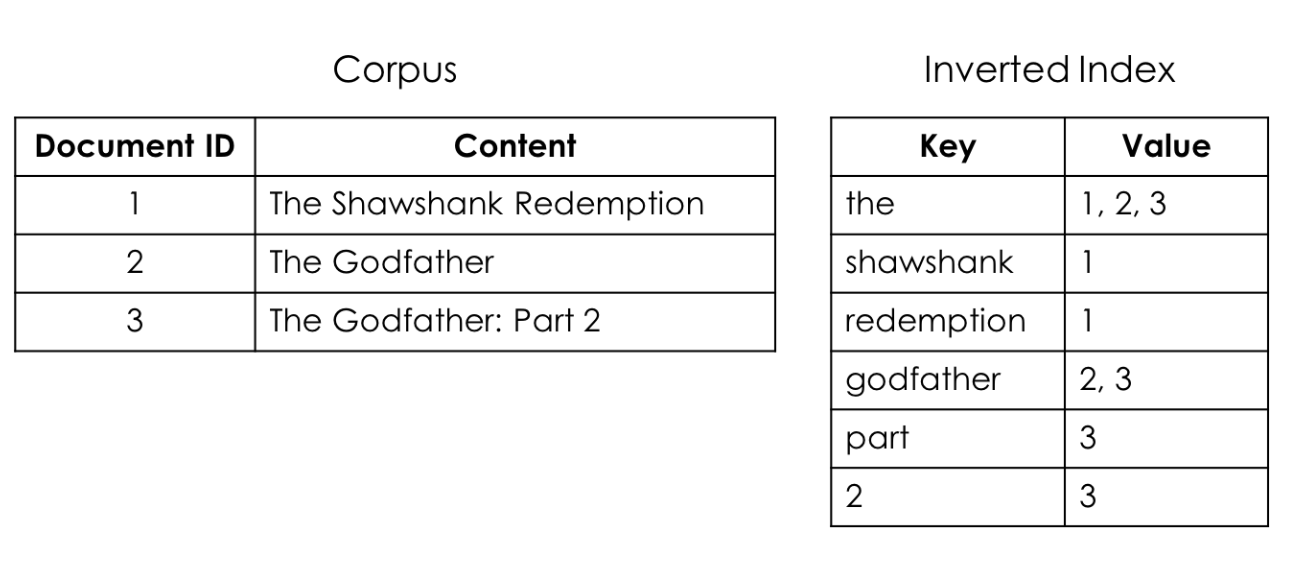
[Elastic Search의 핵심 기능]
=> Inverted Index(역색인) & 형태소 분석
: 빠르게 문서 탐색 가능
* 역색인의 단점 : 대다수의 문서에서 등장하는 단어라면, 오히려 속도가 떨어짐 -> Stopword(불용어)로 등록하면 인덱스에서도 제겋하고 검색어에 등장해도 무시하도록 되어 있음.
[RDBMS 와 Elastic serach 비교]
1. 문법
| 구분 | Elastic search | RDBMS |
| 문법 | GET | SELECT |
| PUT | INSERT | |
| POST | UPDATE, SELECT | |
| DELETE | DELETE | |
| HEAD(인덱스 정보 확인) | ||
| 용어 | 인덱스(Index) | 데이터베이스(DB) |
| 샤드(Shard) | 파티션(Partition) | |
| 타입(Type) | 테이블(Table) | |
| 도큐먼트 | 행 | |
| 필드 | 열 | |
| Mapping | 스키마 | |
| Query DSL | SQL |
참고 1) 6.0이하 버전의 엘라스틱서치에서는 하나의 인덱스 내부 기능에 따라 데이터 분류 후에 여러 개의 타입을 만들어 사용했지만 현재는 하나의 인덱스에 하나의 타입만을 구성해야 합니다.
참고 2) 매핑은 필드의 구조와 제약조건에 대한 명세를 말하며 관계형 DB의 스키마와 같습니다.
참고 3) 관계형 DB와 엘라스틱서치는 인덱스라는 개념을 다르게 사용하는데, 관계형 DB에서 인덱스는 그저 Where절의 쿼리와 Join을 빠르게 만들어주는 보조데이터의 도구로 사용됩니다.
[Elastic Search 설치]
https://www.elastic.co/kr/downloads/elasticsearch
Download Elasticsearch
Download Elasticsearch or the complete Elastic Stack (formerly ELK stack) for free and start searching and analyzing in minutes with Elastic....
www.elastic.co
24.04.21 기준으로 가장 최신 버젼은 8.13.2 버젼이다.

그러나 해당 버젼 설치 시 아래 파일이 실행되지 않는 문제가 있었다. 재설치 / 시스템 환경 설정 - 보안 및 개인정보 보호 / Control + 열기를 해도 실행이 되지 않아, 8.11.2 로 다시 재설치하니 오류가 해결되었다. (Monterey 의 버그인가?)
무튼 위 파일을 실행하고 정상 여부를 확인하기 위해서는 localhost:9200로 접속을 해야한다.
최신 버젼의 elastic은 http가 아닌 https://localhost:9200 으로 접속해야 한다!
위 링크로 접속을 하게 되면 ID와 PW를 입력해야 하는데, 아래 파일일 열리지 않아서 그냥 yml 파일을 수정해버렸다.

elasticsearch-8.11.2/config/elasticsearch.yml을 실행시키고
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
true -> false 로 바꿔준다.

그리고나서 elastic search를 재시작 후 localhost 로 접속하면 아래와 같이 정상 접속을 확인할 수 있다.
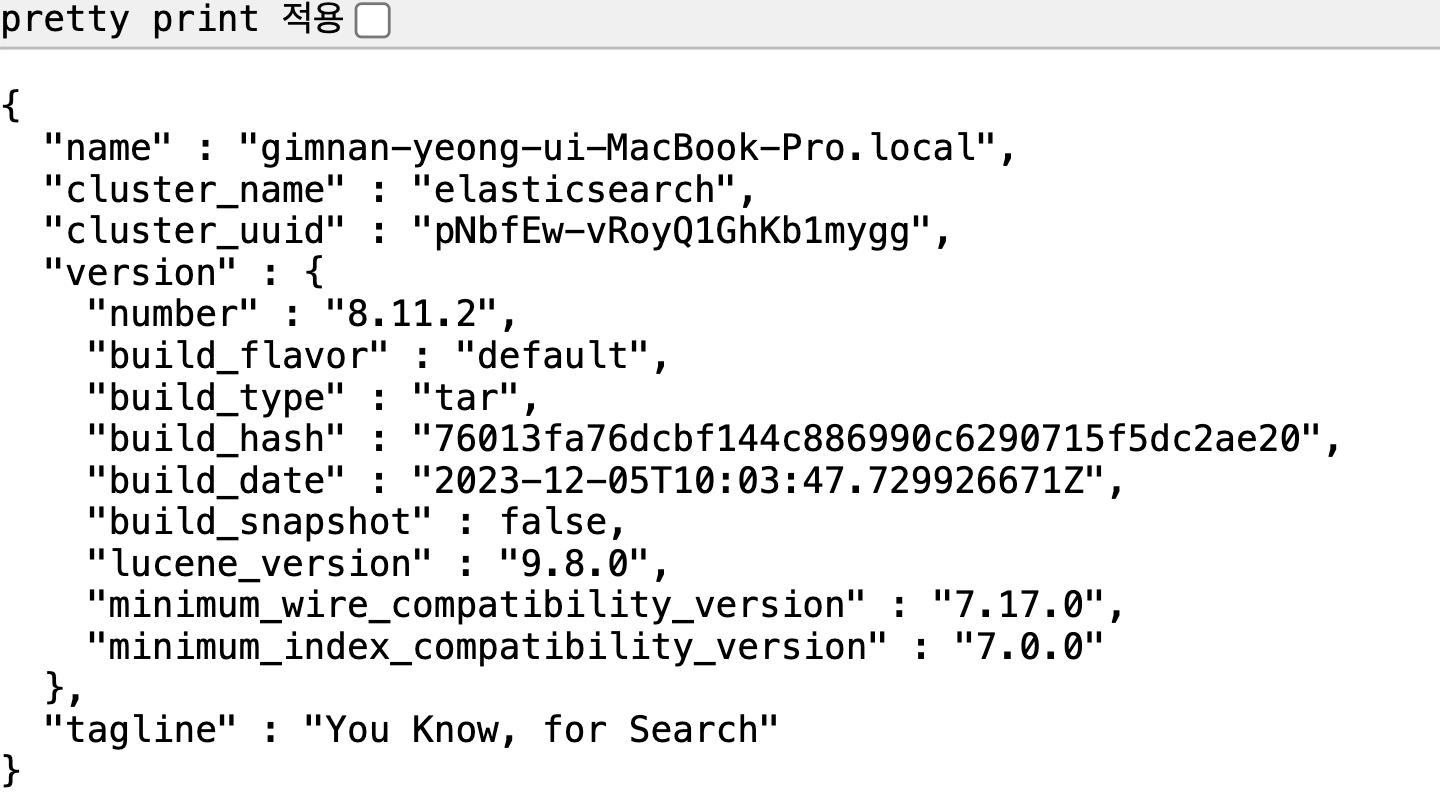
[Kibana 설치]
아래 링크에서 Kibana를 다운한다.
https://www.elastic.co/kr/downloads/past-releases/elasticsearch-8-11-2
Elasticsearch 8.11.2 | Elastic
Release Notes View the detailed release notes here.
www.elastic.co
설치 후 아래 경로에서 Contol을 누르고 열기를 클릭하여 파일을 실행한다.
bin/kibana
*주의 ) Elastic Searh와 버젼이 다르면 아래와 같이 뜬다. 버젼을 맞추도록 하자.
[2024-04-21T13:47:26.658+09:00][ERROR][elasticsearch-service] This version of Kibana (v8.13.2) is incompatible with the following Elasticsearch nodes in your cluster: v8.11.2 @ 192.168.0.2:9200 (127.0.0.1)
실행 후, http://localhost:5601 로 접속해보자.
[실습]
Sample Data를 활용해보자. 이커머스 주문 데이터를 Add 해보았다.
View Data > Discover 를 클릭한다.
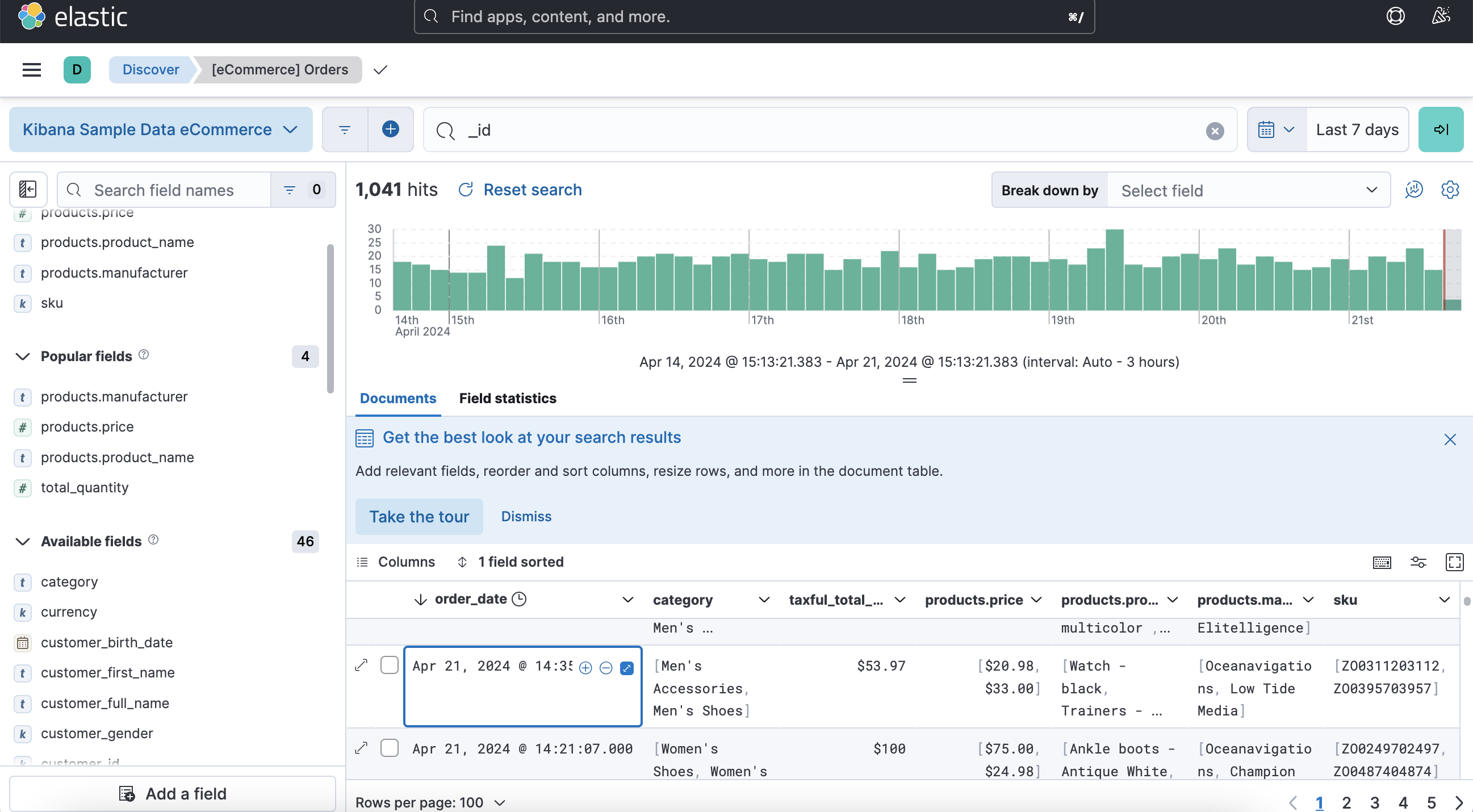
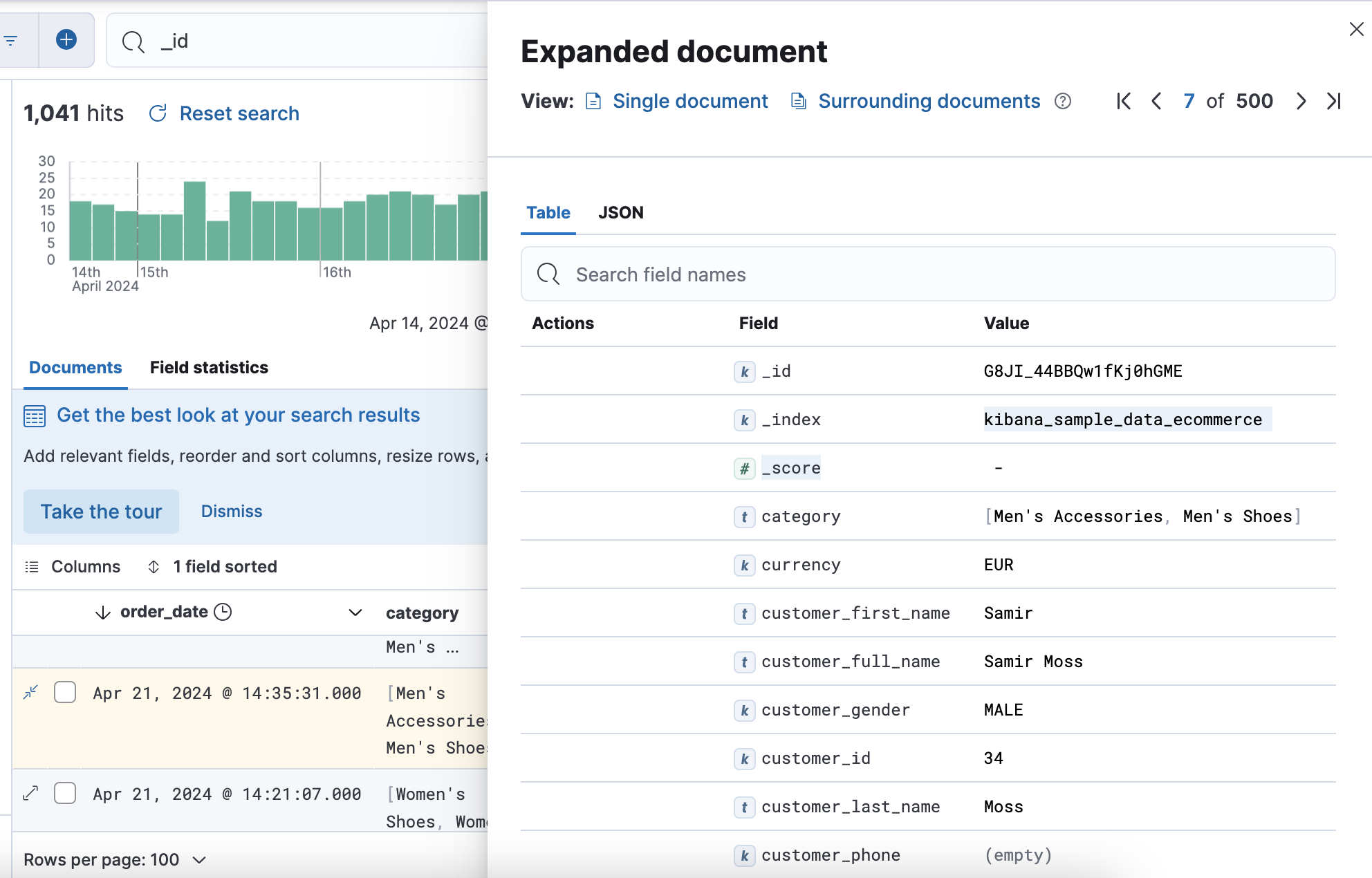
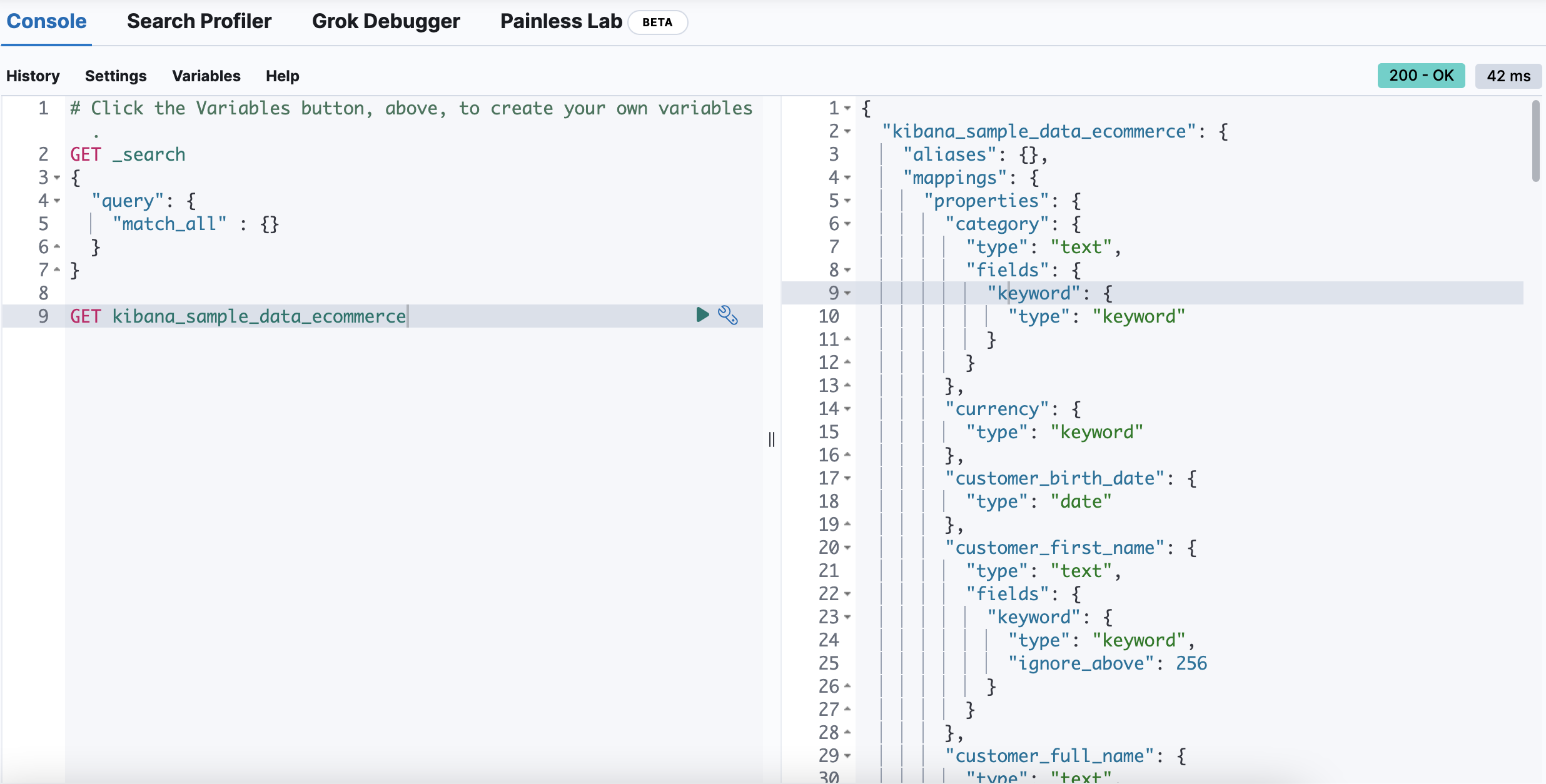
확장 버튼을 누르면 세부 내용을 볼 수 있다. Field(RDBMS의 열) 를 확인할 수 있고, 각 Field 값의 Value도 확인 가능하다.
RDBMS에서는 하나의 열에 하나의 데이터 타입만 가질 수 있었지만, Elastic에서의 필드는 동적이라, 여러개의 데이터 타입을 가질 수 있다.
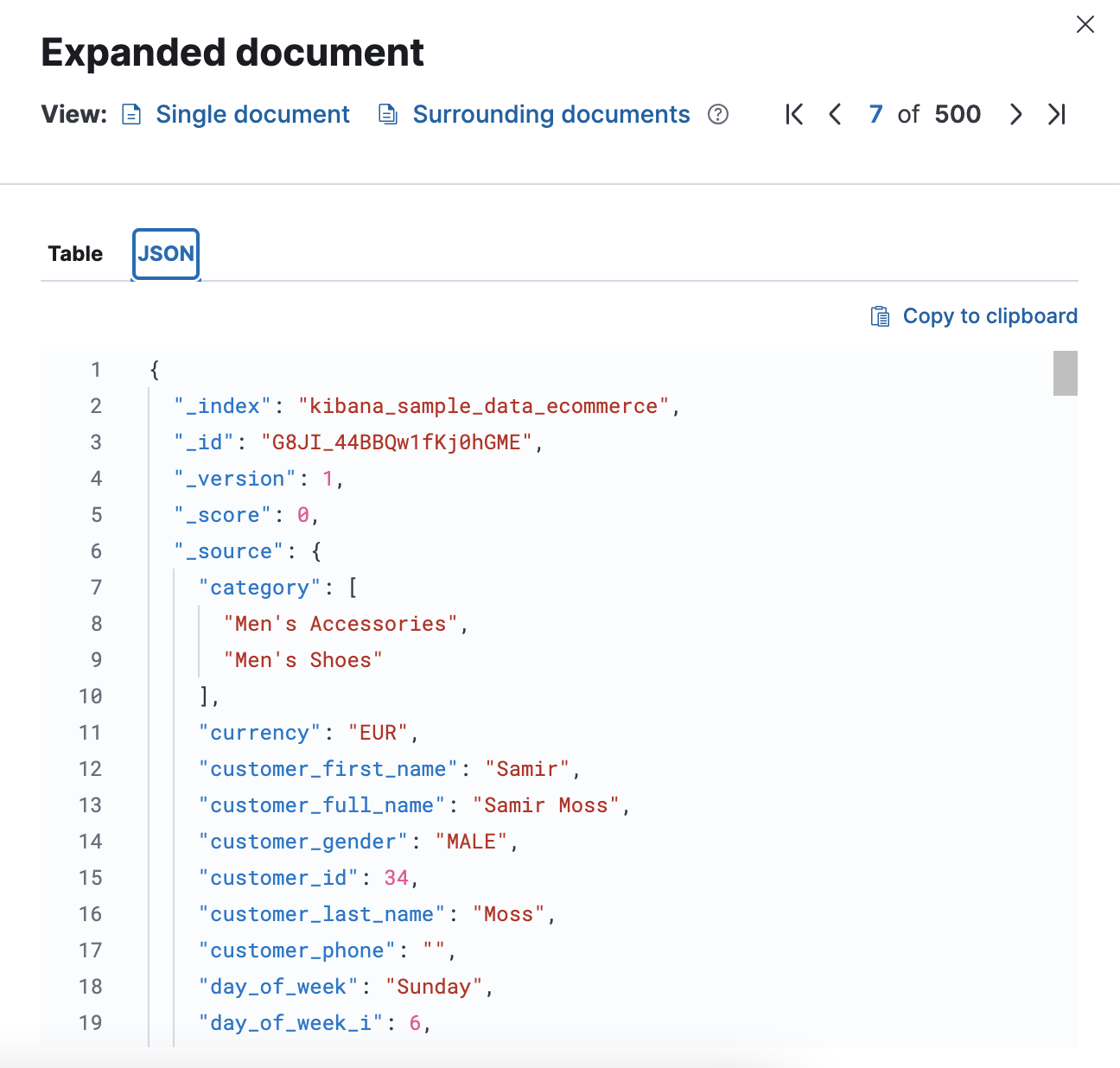
JSON 데이터도 확인 가능하다.
{
"_index": "kibana_sample_data_ecommerce",
"_id": "G8JI_44BBQw1fKj0hGME",
"_version": 1,
"_score": 0,
"_source": {
"category": [
"Men's Accessories",
"Men's Shoes"
],
"currency": "EUR",
"customer_first_name": "Samir",
"customer_full_name": "Samir Moss",
"customer_gender": "MALE",
"customer_id": 34,
"customer_last_name": "Moss",
"customer_phone": "",
"day_of_week": "Sunday",
"day_of_week_i": 6,
"email": "samir@moss-family.zzz",
"manufacturer": [
"Oceanavigations",
"Low Tide Media"
],
"order_date": "2024-04-21T05:35:31+00:00",
"order_id": 564237,
"products": [
{
"base_price": 20.99,
"discount_percentage": 0,
"quantity": 1,
"manufacturer": "Oceanavigations",
"tax_amount": 0,
"product_id": 19840,
"category": "Men's Accessories",
"sku": "ZO0311203112",
"taxless_price": 20.99,
"unit_discount_amount": 0,
"min_price": 10.29,
"_id": "sold_product_564237_19840",
"discount_amount": 0,
"created_on": "2016-12-11T05:35:31+00:00",
"product_name": "Watch - black",
"price": 20.99,
"taxful_price": 20.99,
"base_unit_price": 20.99
},
{
"base_price": 32.99,
"discount_percentage": 0,
"quantity": 1,
"manufacturer": "Low Tide Media",
"tax_amount": 0,
"product_id": 13857,
"category": "Men's Shoes",
"sku": "ZO0395703957",
"taxless_price": 32.99,
"unit_discount_amount": 0,
"min_price": 17.15,
"_id": "sold_product_564237_13857",
"discount_amount": 0,
"created_on": "2016-12-11T05:35:31+00:00",
"product_name": "Trainers - beige",
"price": 32.99,
"taxful_price": 32.99,
"base_unit_price": 32.99
}
],
"sku": [
"ZO0311203112",
"ZO0395703957"
],
"taxful_total_price": 53.98,
"taxless_total_price": 53.98,
"total_quantity": 2,
"total_unique_products": 2,
"type": "order",
"user": "samir",
"geoip": {
"country_iso_code": "AE",
"location": {
"lon": 55.3,
"lat": 25.3
},
"region_name": "Dubai",
"continent_name": "Asia",
"city_name": "Dubai"
},
"event": {
"dataset": "sample_ecommerce"
}
},
"fields": {
"products.manufacturer": [
"Oceanavigations",
"Low Tide Media"
],
"products.base_unit_price": [
20.984375,
33
],
"products.discount_amount": [
0,
0
],
"type": [
"order"
],
"products.discount_percentage": [
0,
0
],
"products._id.keyword": [
"sold_product_564237_19840",
"sold_product_564237_13857"
],
"day_of_week_i": [
6
],
"total_quantity": [
2
],
"taxless_total_price": [
53.96875
],
"total_unique_products": [
2
],
"geoip.continent_name": [
"Asia"
],
"sku": [
"ZO0311203112",
"ZO0395703957"
],
"customer_full_name.keyword": [
"Samir Moss"
],
"category.keyword": [
"Men's Accessories",
"Men's Shoes"
],
"products.taxless_price": [
20.984375,
33
],
"products.quantity": [
1,
1
],
"customer_first_name": [
"Samir"
],
"products.price": [
20.984375,
33
],
"customer_phone": [
""
],
"geoip.region_name": [
"Dubai"
],
"customer_full_name": [
"Samir Moss"
],
"geoip.country_iso_code": [
"AE"
],
"order_id": [
"564237"
],
"products._id": [
"sold_product_564237_19840",
"sold_product_564237_13857"
],
"products.product_name.keyword": [
"Watch - black",
"Trainers - beige"
],
"products.product_id": [
19840,
13857
],
"products.category": [
"Men's Accessories",
"Men's Shoes"
],
"products.manufacturer.keyword": [
"Oceanavigations",
"Low Tide Media"
],
"manufacturer": [
"Oceanavigations",
"Low Tide Media"
],
"products.unit_discount_amount": [
0,
0
],
"customer_last_name": [
"Moss"
],
"geoip.location": [
{
"coordinates": [
55.3,
25.3
],
"type": "Point"
}
],
"products.product_name": [
"Watch - black",
"Trainers - beige"
],
"products.tax_amount": [
0,
0
],
"manufacturer.keyword": [
"Oceanavigations",
"Low Tide Media"
],
"products.min_price": [
10.2890625,
17.15625
],
"currency": [
"EUR"
],
"products.taxful_price": [
20.984375,
33
],
"products.base_price": [
20.984375,
33
],
"email": [
"samir@moss-family.zzz"
],
"day_of_week": [
"Sunday"
],
"customer_last_name.keyword": [
"Moss"
],
"products.sku": [
"ZO0311203112",
"ZO0395703957"
],
"products.category.keyword": [
"Men's Accessories",
"Men's Shoes"
],
"geoip.city_name": [
"Dubai"
],
"customer_first_name.keyword": [
"Samir"
],
"order_date": [
"2024-04-21T05:35:31.000Z"
],
"products.created_on": [
"2016-12-11T05:35:31.000Z",
"2016-12-11T05:35:31.000Z"
],
"category": [
"Men's Accessories",
"Men's Shoes"
],
"customer_id": [
"34"
],
"user": [
"samir"
],
"customer_gender": [
"MALE"
],
"event.dataset": [
"sample_ecommerce"
],
"taxful_total_price": [
53.96875
]
}
}
Dashboard 에서 다양한 Summary 데이터를 확인할 수 있다.
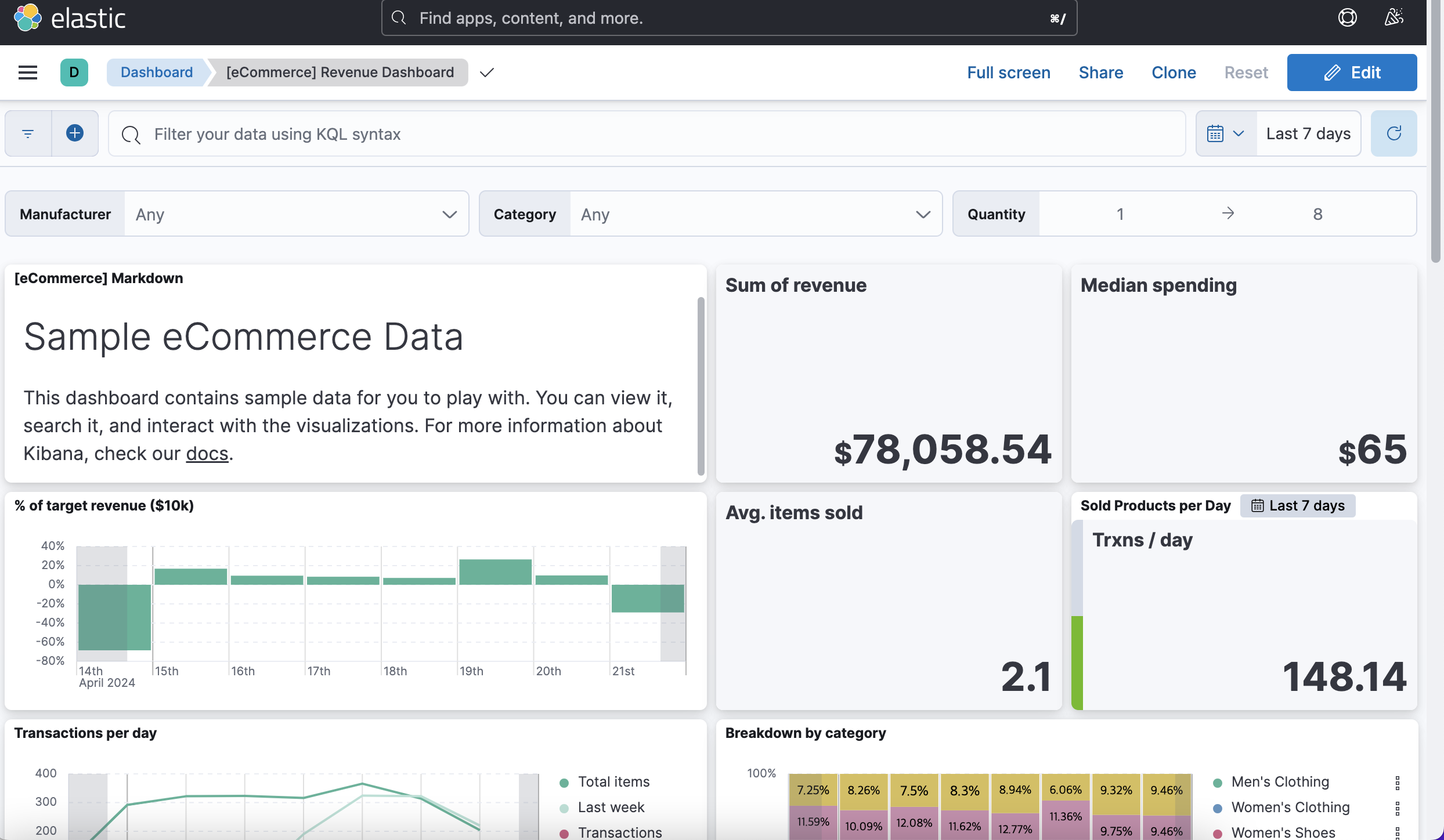
이제 실습을 해보자.
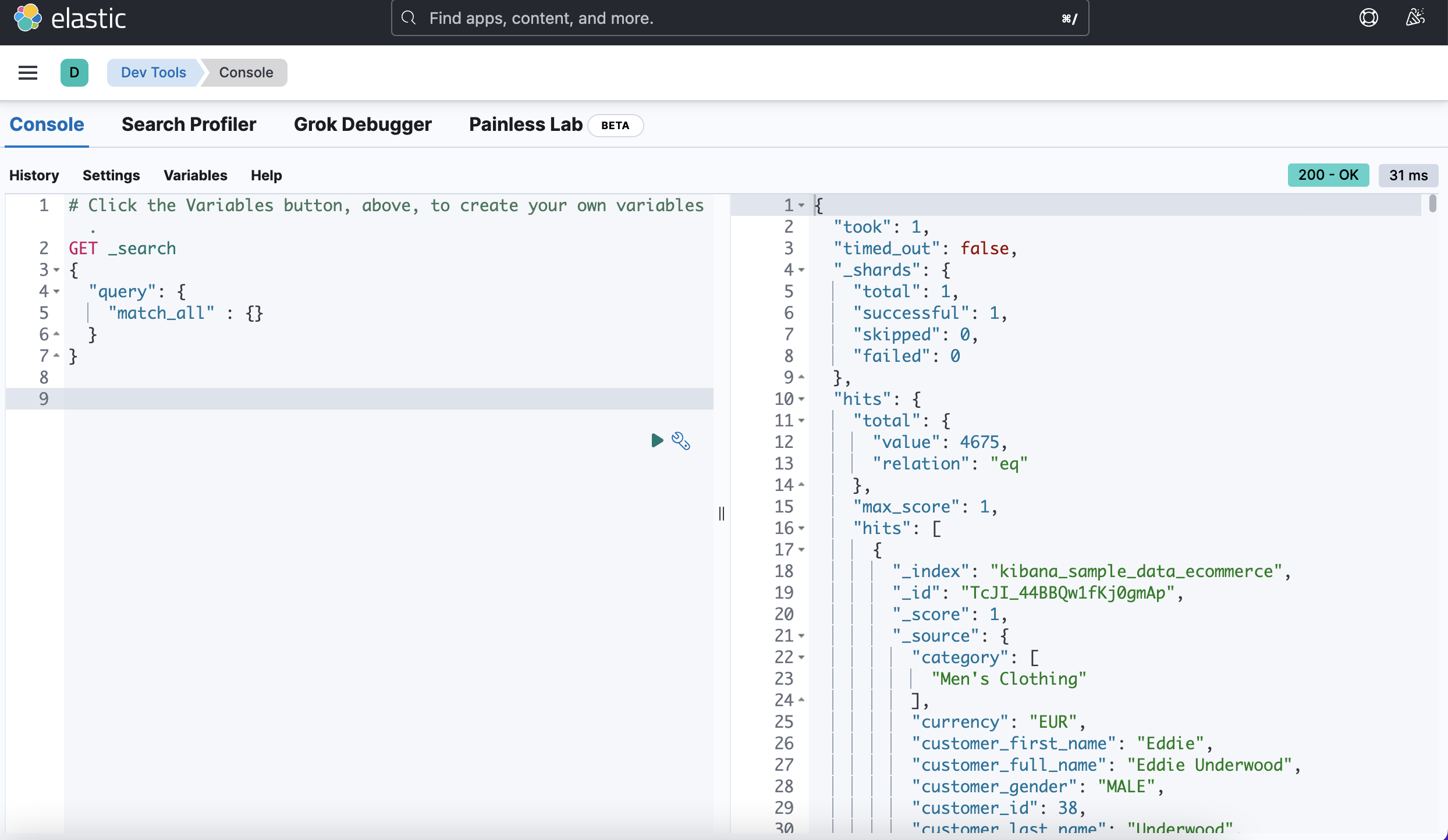
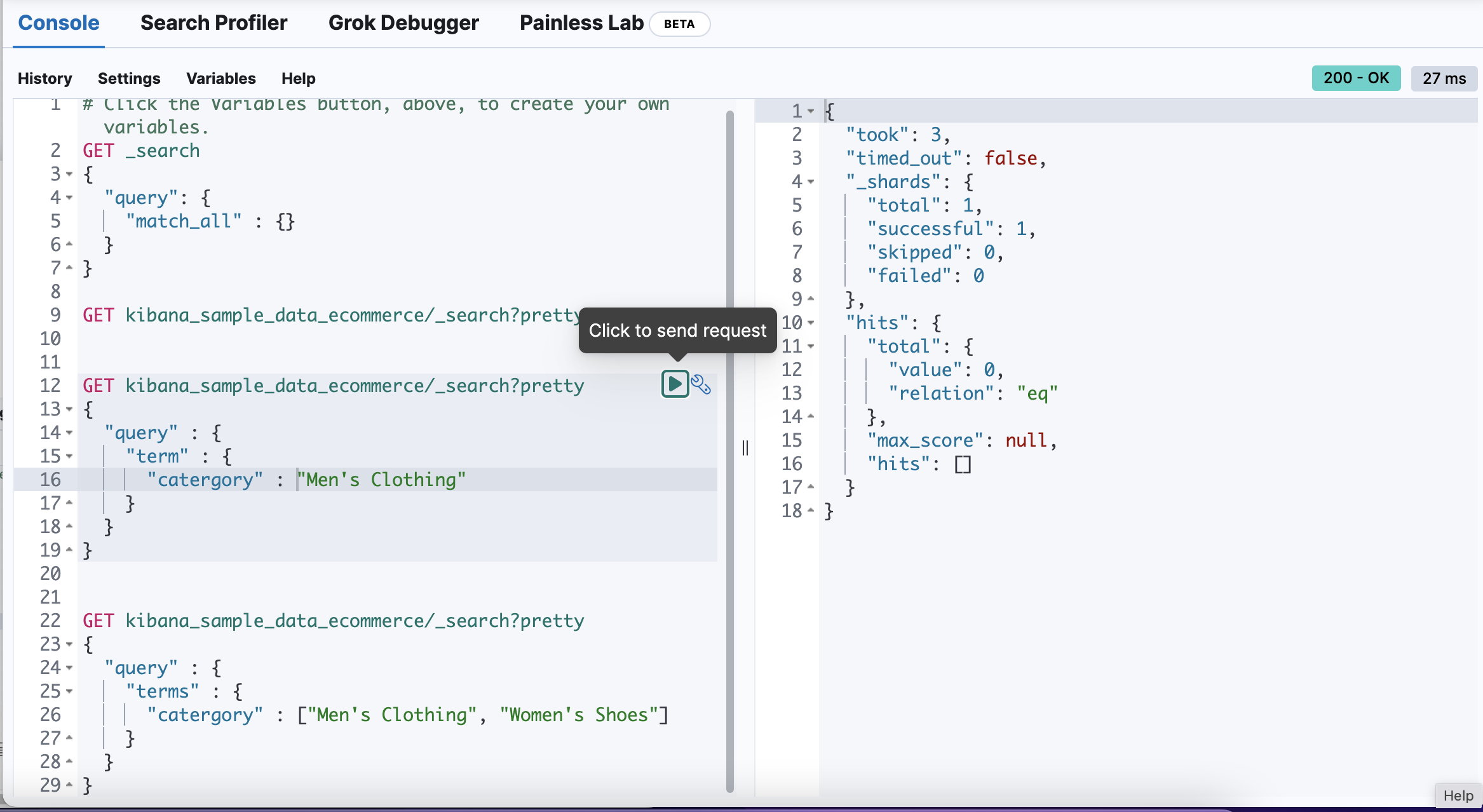
- took : 검색 응답 시간
- time_out : 검색이 time out 되었는지 여부
- _shards : 검색을 수행한 샤드 정보
- total : 검색을 수행한 총 샤드 수
- successful : 검색 수행을 성공한 샤드 수
- failed : 검색 수행을 실패한 샤드 수
- hits
- total : 검색 매칭에 성공한 도큐먼트 수
- max_score : 매칭에 성공한 도큐먼트중 가장 높은 점수
=======================
참고
'ETC' 카테고리의 다른 글
| [엑셀 기초] - 직장인 엑셀 실무 기초 (업무가 최소 2배 편해지는 엑셀 활용법) (0) | 2024.01.28 |
|---|---|
| 머신러닝(Machine Learning)이란? (1) | 2021.02.01 |
| [C++] 배열 Syntax 주의할 점 (0) | 2021.01.25 |
| Pixlr Editor로 색상코드(HEX) 알아내기 (0) | 2021.01.16 |